We’ve already begun to design our microservices in a resilient fashion. To start, none of them talk directly to each other via HTTP, so if one microservice crashes, other microservices can continue to function in isolation until the crashed microservice restarts. Furthermore, each microservice owns a separate data store.
Currently, we use the same SQL server for our Order and Product microservices, but we can separate these into completely separate servers so there is no chance of a SQL server outage affecting both of our microservices. However, it’s not perfect. What happens if our RabbitMQ service crashes and our microservices can’t publish events? Or what happens if our SQL server crashes and we attempt to read data from our database?
As things stand, our microservices themselves would crash, which is known as failure propagation. When one service or component fails, we don’t want this to prevent other services from continuing to function. Instead, we need to introduce a mechanism by which our services retry the execution of the event publishing or the SQL read when we encounter an issue.
Retry Mechanisms
If our microservice fails to publish an event to RabbitMQ or reads some data from SQL, we may want to retry the action as we could have encountered a transient issue. However, it isn’t as simple as continuously retrying the event publish or data read until it succeeds. First and foremost, if the issue is a more severe one, such as our RabbitMQ server being offline, retries will not help. Secondly, the act of retrying a request puts extra stress on the receiver. This extra stress can therefore be compounded if we continue to retry, and grows exponentially when we have multiple services retrying requests. Let’s take the example of our RabbitMQ service, with multiple publishers:
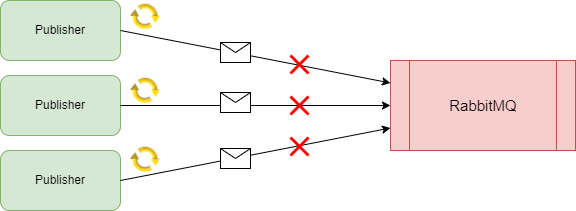
If the RabbitMQ server is already struggling due to a lack of compute resources, retrying requests is going to add more load to the server and eventually cause a complete outage, which we want to avoid. To combat this, we need to be smart with our retry mechanisms. First, we can use an exponential backoff mechanism, whereby the interval between retries grows larger:
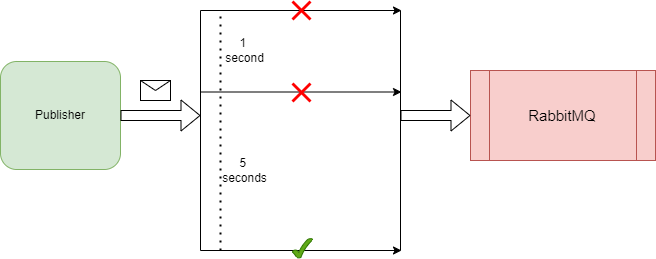
This ensures we don’t add extra stress on the server and increase the chance of the request succeeding. To take it a step further, we can introduce a circuit breaker mechanism, so that after a certain number of retry attempts, we stop retrying the request and assume the server is in a crashed state and any number of retry attempts won’t make a difference. This is a common strategy with HTTP requests. If 3 attempts fail, it’s unlikely the 4th or 5th will succeed, therefore we design for this and stop retrying after the 3rd attempt:
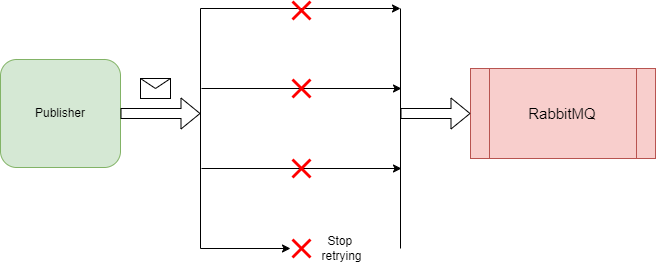
How we determine and implement the retry mechanisms will depend on the component we are sending requests to. Our retry mechanism for publishing events to RabbitMQ will differ from how we retry SQL connections, but the fundamental principle remains the same. So with that, let’s begin implementing some retry mechanisms in our microservices and improving our resiliency.