With a basic understanding of what a microservice is and how we can combine microservices to provide a functional system, we’ve started to touch on the benefits that implementing microservices gives us, such as:
- Easily maintainable by a small number of developers
- Enables continuous delivery
- Individually scalable.
Let’s dive a bit deeper into these benefits.
Easy Maintainability of Microservices
There are a couple of factors that make microservices easily maintainable. First and foremost, because they are singularly focused, they have very specific reasons to change. External factors are vastly less likely to cause us to refactor microservices, given they are implemented correctly. This allows us, as developers, to adhere to one of the fundamental principles of software development – the Single Responsibility Principle.
Furthermore, microservices own their data store and don’t allow other services to interact directly with their data. In addition, a microservice codebase is generally small, which means we as developers can more easily grasp the domain a microservice is focusing on. This provides much more confidence when it comes to refactoring microservices or introducing new functionality.
Due to this singular focus and easy comprehension of what a microservice does, usually, a single team can own and maintain a couple of microservices. This provides the team with ownership of these microservices and empowers them to quickly diagnose and resolve issues and bugs as they arise in production, rolling out fixes in a short space of time, which is the next benefit we’ll cover.
Continuously Delivering Value
Since a single microservice has a small blast radius and focuses on a specific domain, it enhances the speed at which developers can deliver new code for the service. On top of this, we can more quickly understand bugs in the system and resolve them. Having small services enables us to write more automated testing for our service.
We may still have external dependencies, but these should be fewer than in a monolithic codebase and much easier to mock. Having well-tested services further enables us to deliver new features and fixes to our users, as we have the confidence that the code we write isn’t going to introduce new regressions in the system. One of the greatest enablers for providing continuous delivery in a microservice is that because we have well-defined and well-tested boundaries, we can deploy new, backward-compatible versions of our service at any time. We’ll touch on backward compatibility later on, but let’s understand a bit better how exactly microservices enable continuous delivery.
Let’s take a monolithic e-commerce application for example, where we have all the code and functionality in a single codebase. If we want to roll out a new feature to our payment service, such as enabling users to pay via the latest cryptocurrency, we need to deploy our whole application. But we’ve only introduced new code in the part of our application that handles payment: 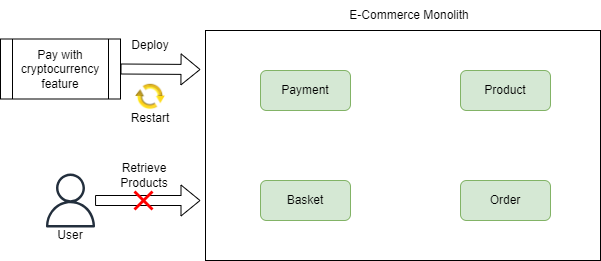
Our basket, product, and order modules, although unchanged, are restarted as we have everything in a single deployable. Now, if we instead designed our e-commerce application as a set of independent microservices, we could trivially introduce this new functionality to our payment microservice and deploy it separately to all our other microservices. Our basket, product, and order microservices don’t care, or need to know, about the ability to pay with a new cryptocurrency, so deploying this new functionality to our payment microservice does not affect them. So they can continue functioning and serving users while our payment microservice is updated: 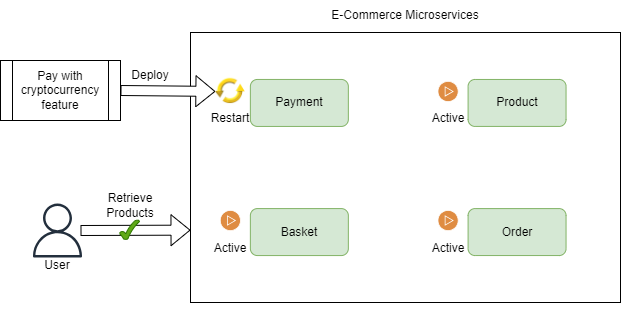
A single team owns a microservice and can be easily deployed independently due to thorough testing. Because of this, the velocity of delivering value to our users increases, potentially enabling multiple deployments a day. We won’t cover all the intricacies of actually achieving multiple deployments in a day, as there are a lot of factors that come into play, but we will touch on some of the most important later on, such as being resilient and asynchronous microservices.
Highly Scalable and Available
When we talk about scalability, we mean the ability to meet the demands of our system and users. Generally, when we build applications that serve a non-trivial amount of users, we inevitably hit bottlenecks somewhere in the system. This can be due to a large number of factors, such as the computing power available to the system. With a monolithic system, it can be very difficult to pinpoint where this bottleneck lives, as our whole application shares the same computing power.
Furthermore, to address the bottleneck, we need to scale up (provide more CPU/RAM) or scale out (introduce more instances of our application) the application as a whole, which can be costly. On the flipside, in a microservices-based system, given we have the correct monitoring in place, we can much more easily diagnose where the bottleneck lives, usually being able to pinpoint the precise microservice causing the issues. This is hugely beneficial, as we have a bunch of options to address this bottleneck.
We can simply scale up or scale out the single microservice to fix our bottleneck. Because each of our microservices has its computing power, we can increase the compute for the single microservice we need to, without needing to touch any of our other microservices. This greatly improves efficiency and cost. Furthermore, because we can now pinpoint where the bottleneck is if it is due to poorly optimized code, we have a much easier time understanding the issue and going about resolving it, while in a monolithic system, this would be much more difficult.